Daily estimated excess deaths 7-day trailing average
EXPLAINER
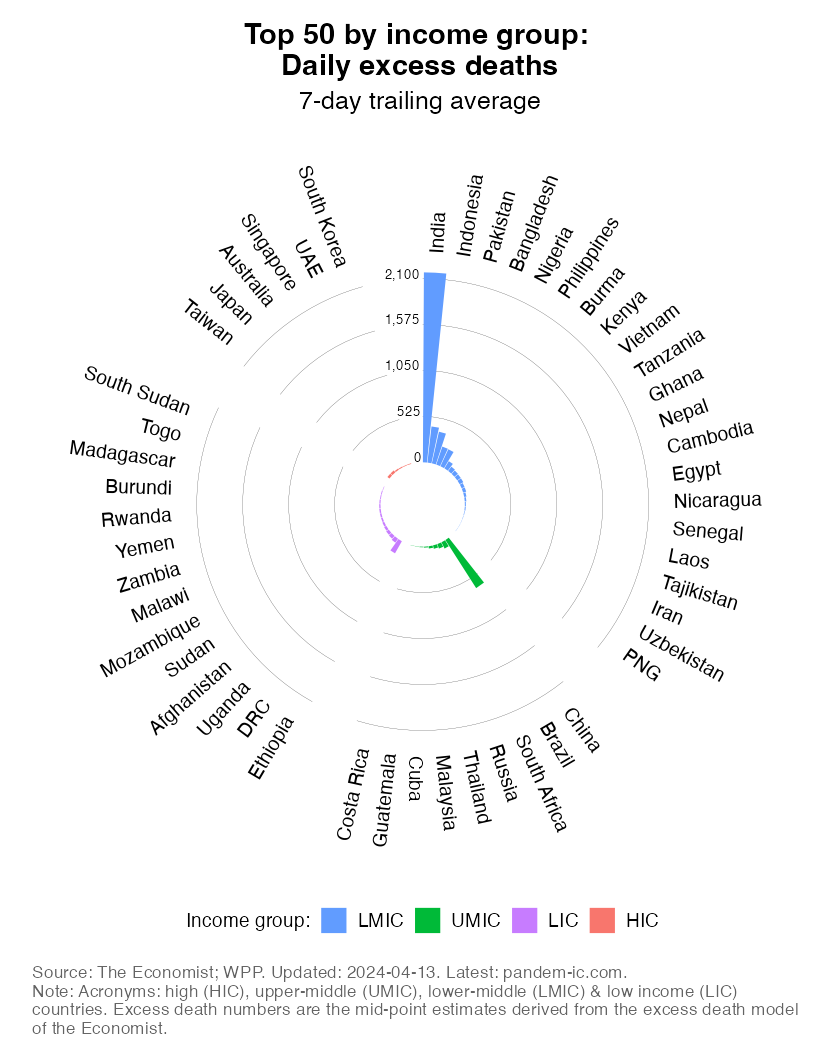
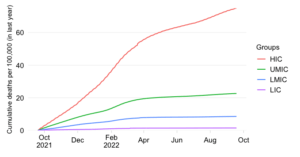
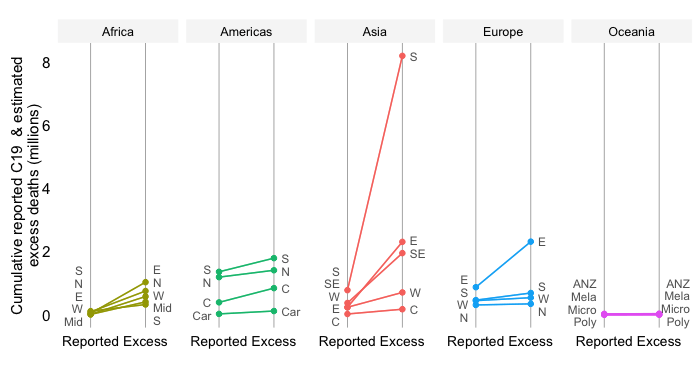
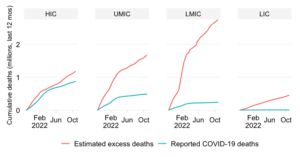
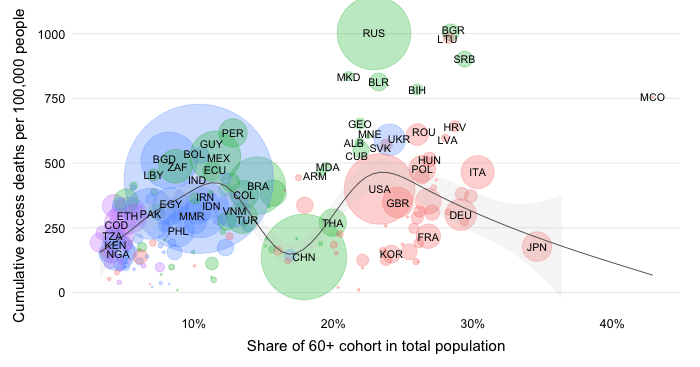
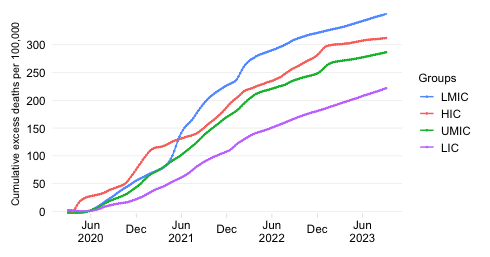
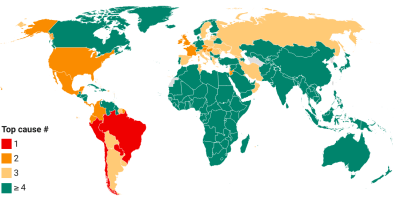
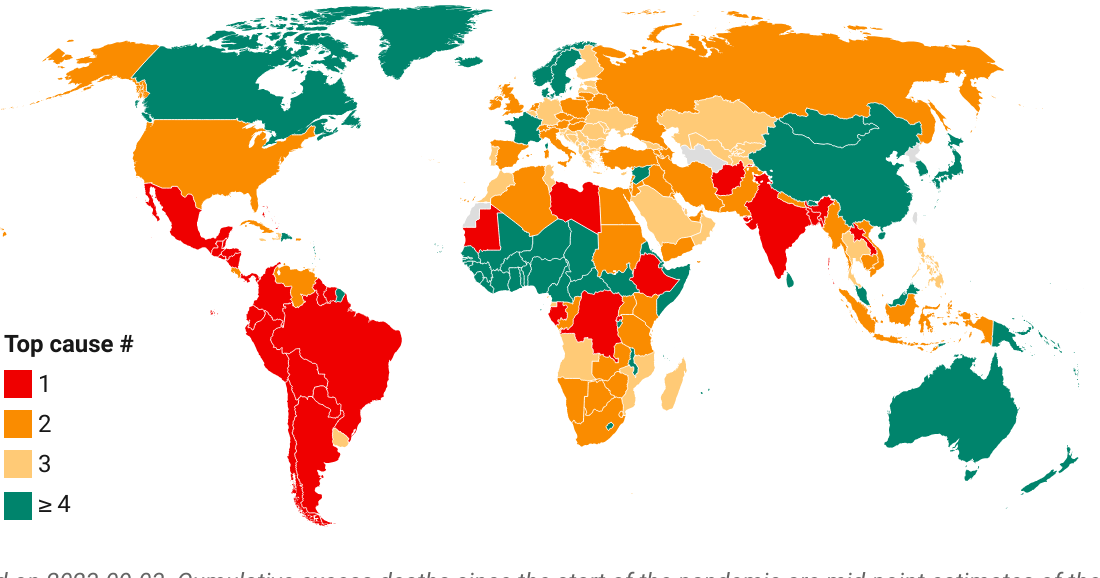
This chart takes a snapshot of the Top 50 countries which currently have the highest estimated daily excess mortality in absolute numbers. It groups the countries by World Bank income group and ranks them within each region by the daily absolute excess mortality toll. The comparison of countries among their per capita income peers (as captured by the World Bank income classification) is useful to account for differences in structural features between income groups.
The excess death estimates are the mid-point estimates derived from excess death model of The Economist, which fills data gaps on the basis of a machine-learning algorithm that learns from official excess mortality date, where available, and over 100 other statistical indicators. The indicator is available on a weekly frequency and its values are converted into a smoothed average. For more details on methods and sources, check out the excess mortality entry in the list of background notes below.
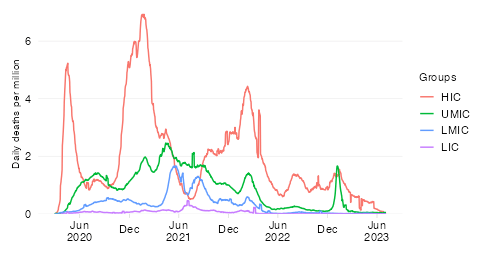
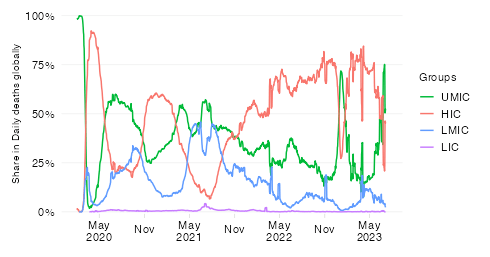
The absolute expression of the excess mortality toll is useful to highlight the the contribution of countries or groups of countries to the global total. Excess mortality rates, which express the absolute toll relative to population size, provide an indication of performance controlling for population size. The absolute numbers however take the view that a life lost is a life lost, no matter where the person happened to live. It offers a valuable perspective on the absolute scale of the pandemic’s death toll.