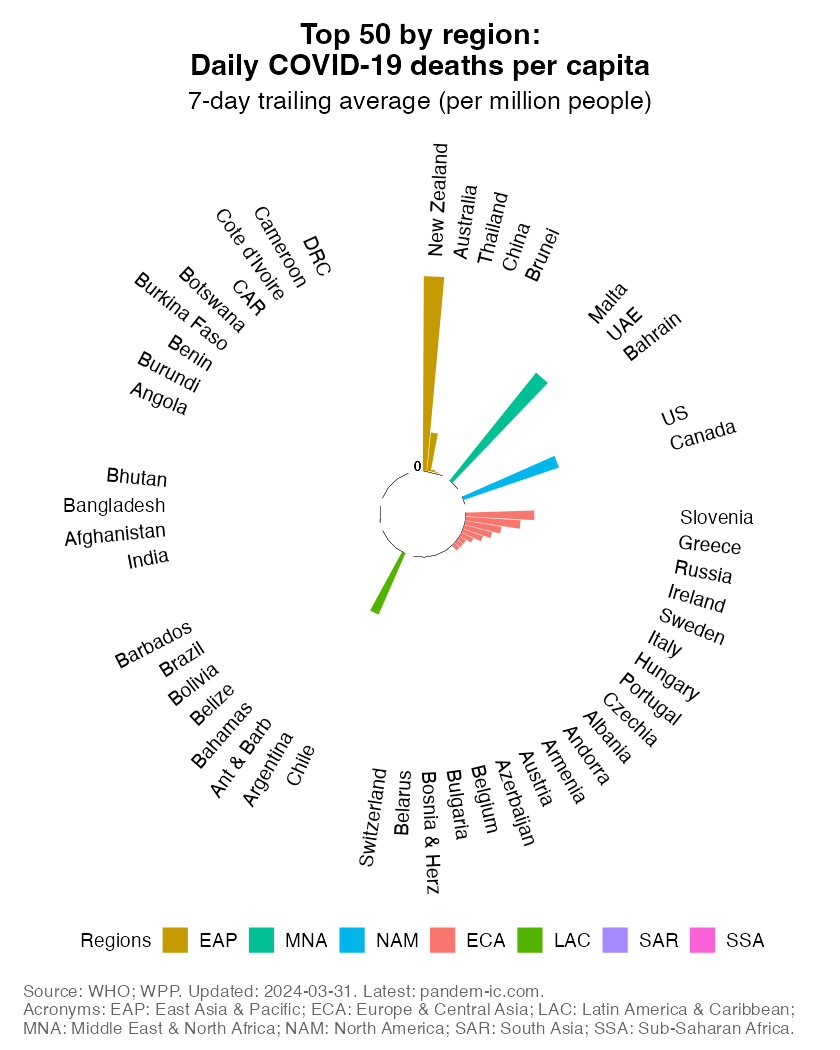
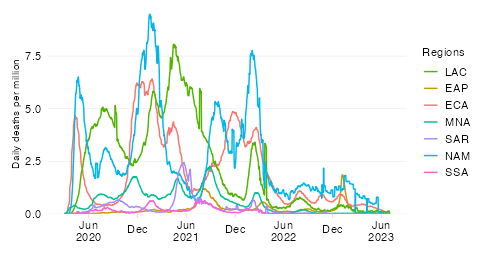
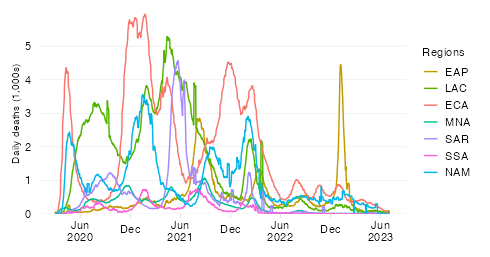
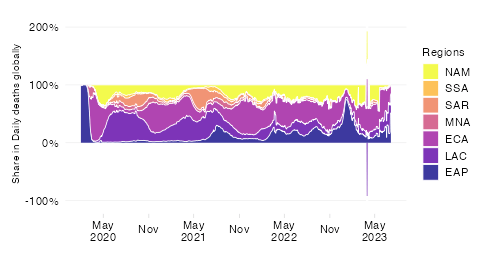
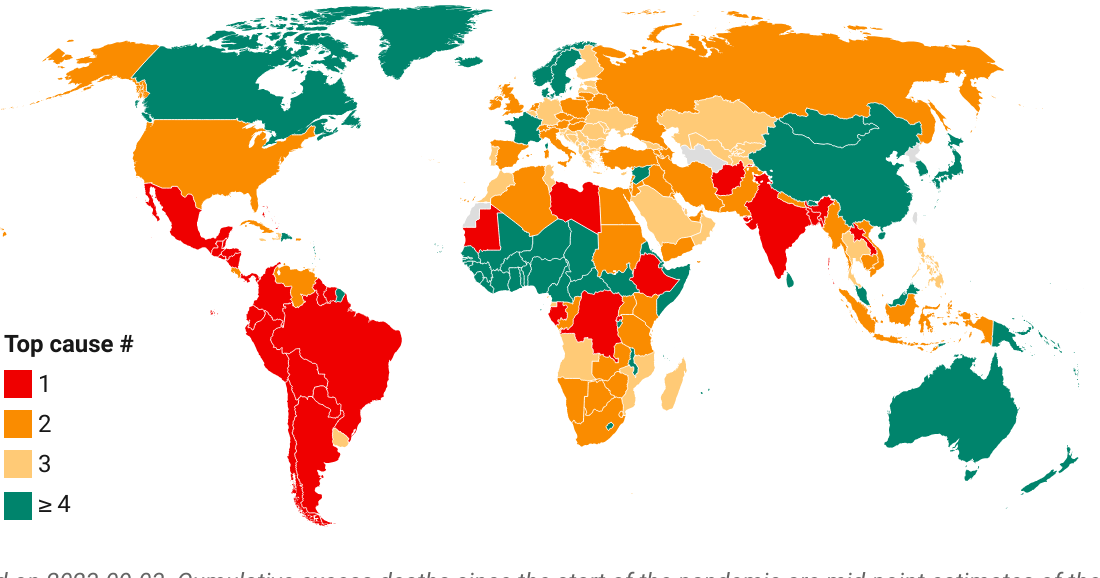
Top 50: Daily deaths per capita by World Bank region
TRACKER
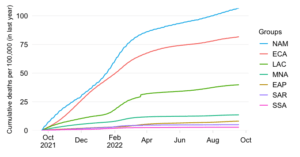
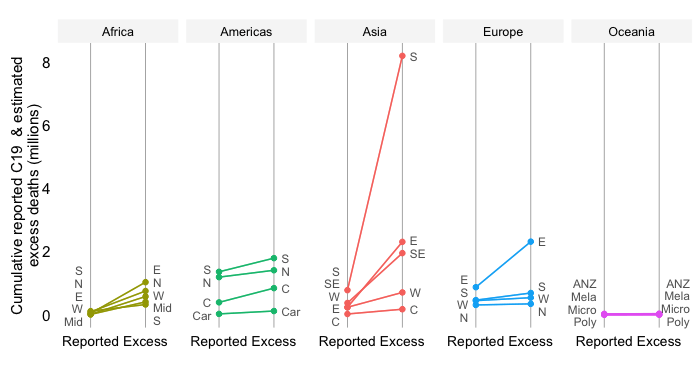
Mortality by World Bank region
Top 50: Daily deaths per capita by World Bank region
Updated daily
Daily confirmed COVID-19 deaths per million people 7-day trailing average
EXPLAINER
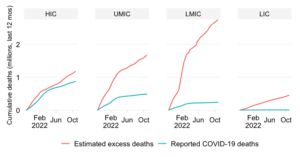
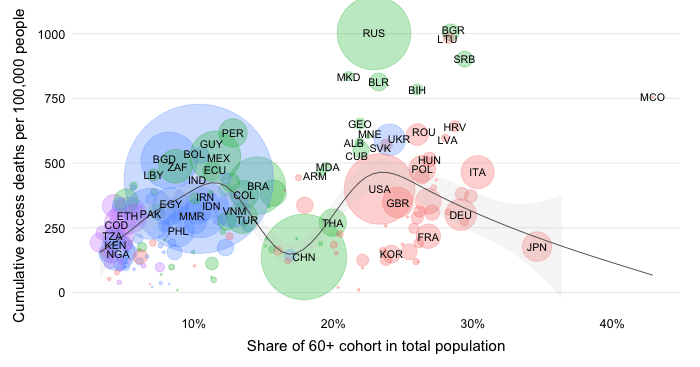
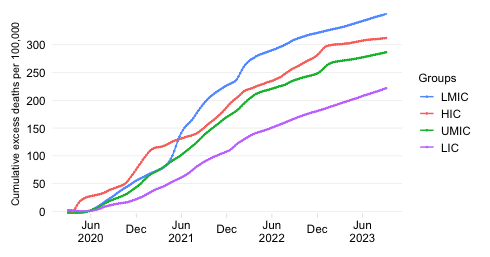
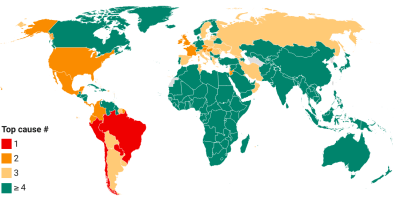
This chart takes a snapshot of the Top 50 countries which currently have the highest daily COVID-19 mortality rate. It groups the countries by World Bank region and ranks them within each region by the mortality rate.
The mortality rate expresses COVID-19 fatalities relative to the size of the population. To remove intra-week volatility in the reported data, the indicator is transformed into a 7-day trailing average (the average value of the latest observation and the preceding 6 days).
By relating COVID-19 mortality to population size, we get a measure of the burden of disease. In contrast to the absolute mortality toll, the mortality rate provides an indication of the performance of country or group of countries in terms of protecting its population against death with COVID as the underlying cause.