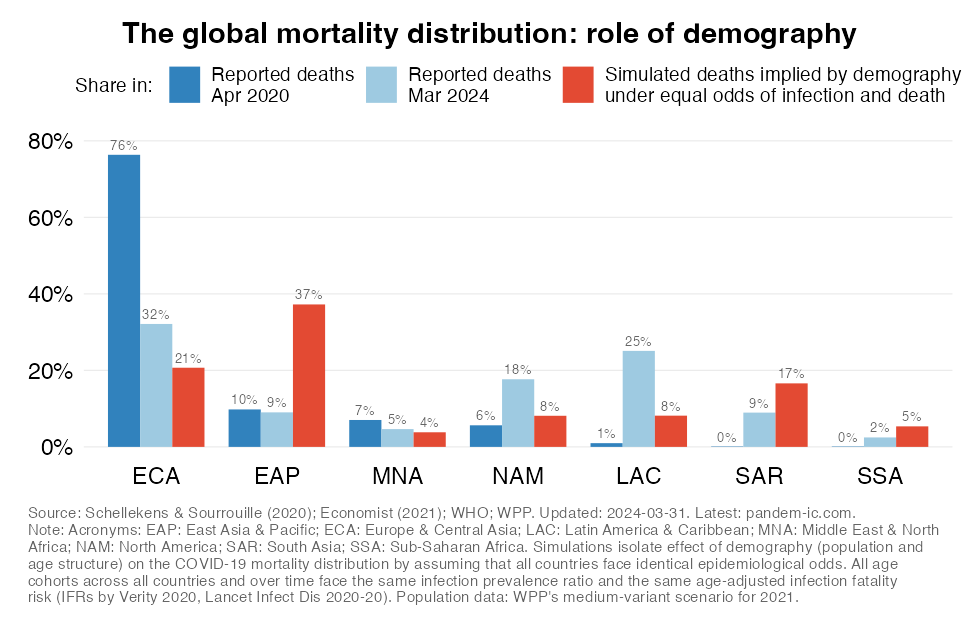
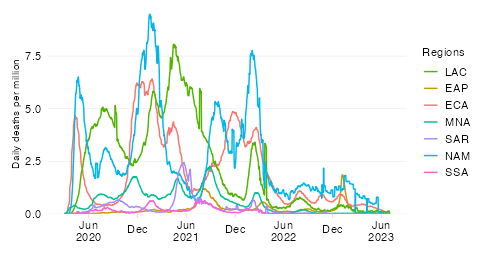
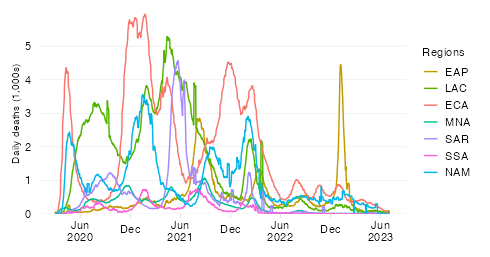
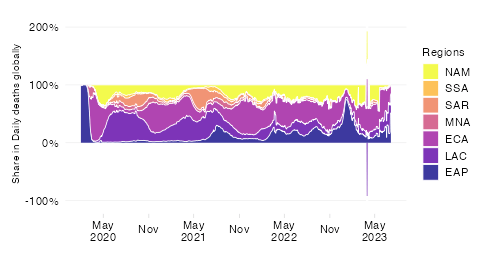
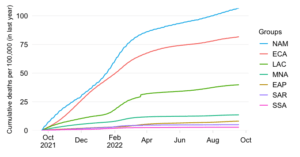
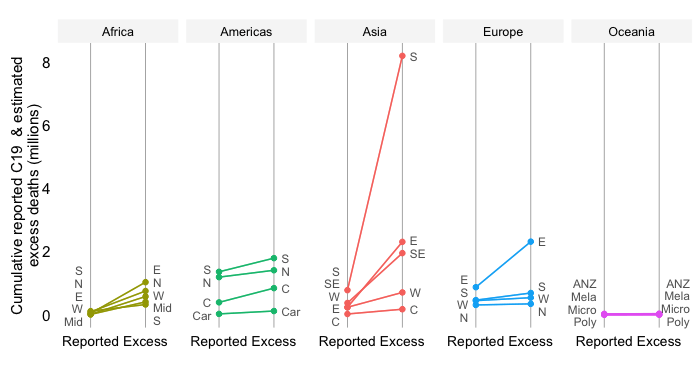
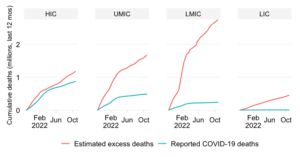
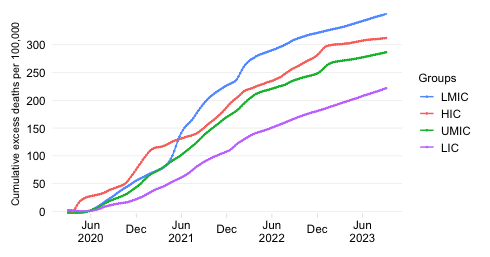
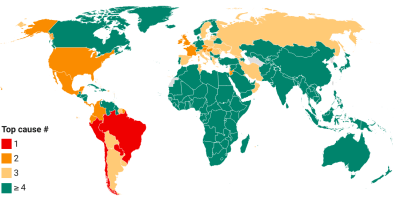
Share in cumulative confirmed COVID-19 deaths since start of the pandemic
EXPLAINER
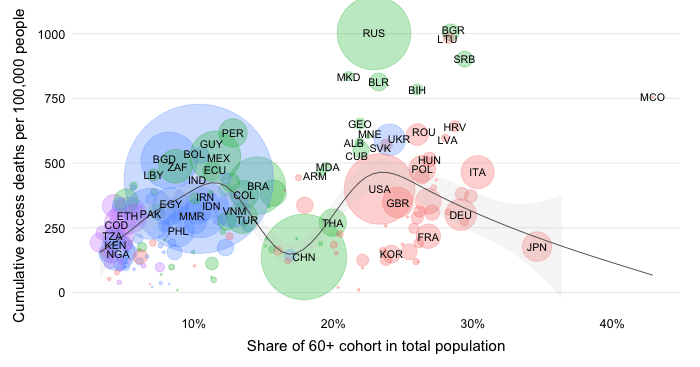
Demography acts as a beacon towards which pandemic mortality outcomes gravitate. Accordingly, demography (the combination of population size and age structure) represents a structural trend that has supported (and will continue to support) a shift of the mortality burden of the pandemic towards the developing world.
The simulations in the chart (red bar on the right) isolate the effect of demography on mortality outcomes across World Bank regions as summarized in their share in the global death toll. The simulation reflects a counterfactual where all other variables are held constant. That means everyone gets infected at the same rate and faces the same age-adjusted infection fatality risk (capturing the age-discriminating nature of COVID-19).
The counterfactual simulations are a thought experiment to interpret the role of demography. They should not be interpreted as forecasts as there are many other confounding factors that affect mortality. At the same time, we do see that the mortality share has evolved rather dramatically since the start of the pandemic into the direction of what these demographic beacons suggest (the dark and light blue bars on the left and in the middle).
The simulations suggest that given their older age structure we should expect that regions with a large share of seniors in their total population attract a higher share of mortality than their share in global population.
More details on the methodology underpinning this chart can be found in our paper.