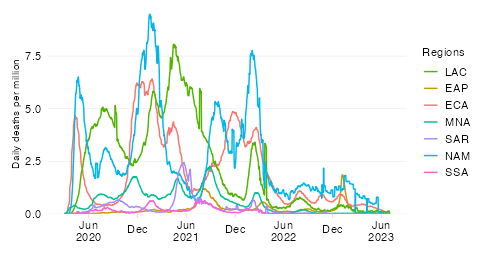
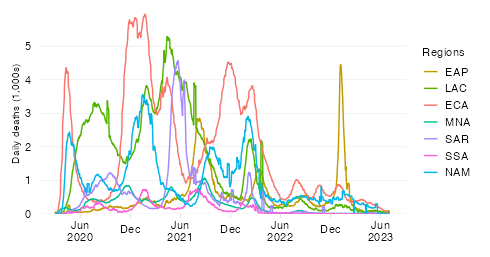
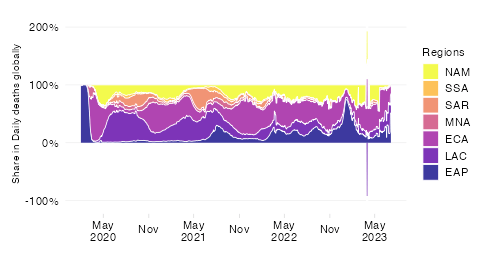
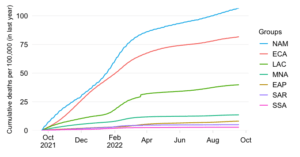
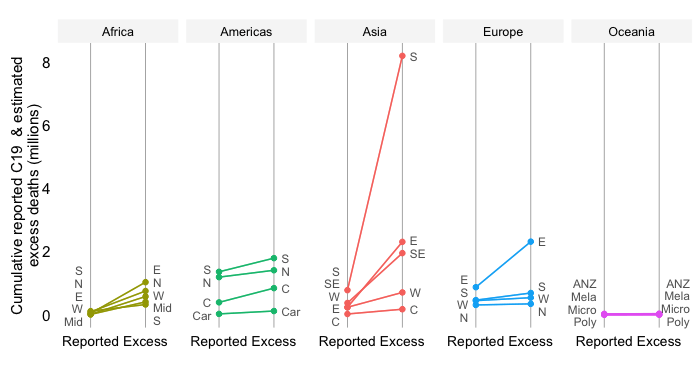
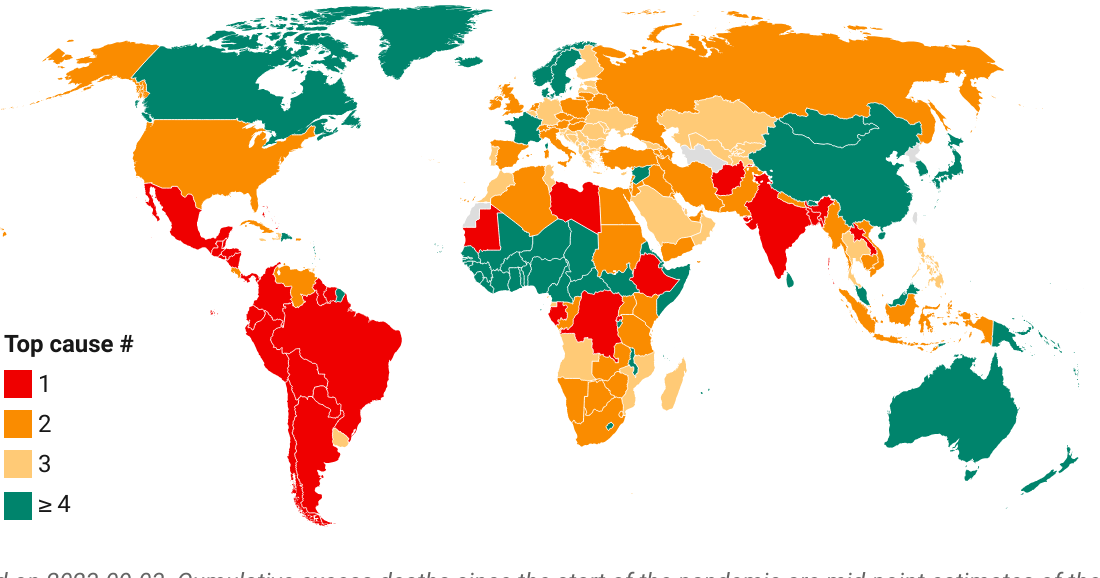
Share in cumulative confirmed COVID-19 deaths since start of the pandemic
EXPLAINER
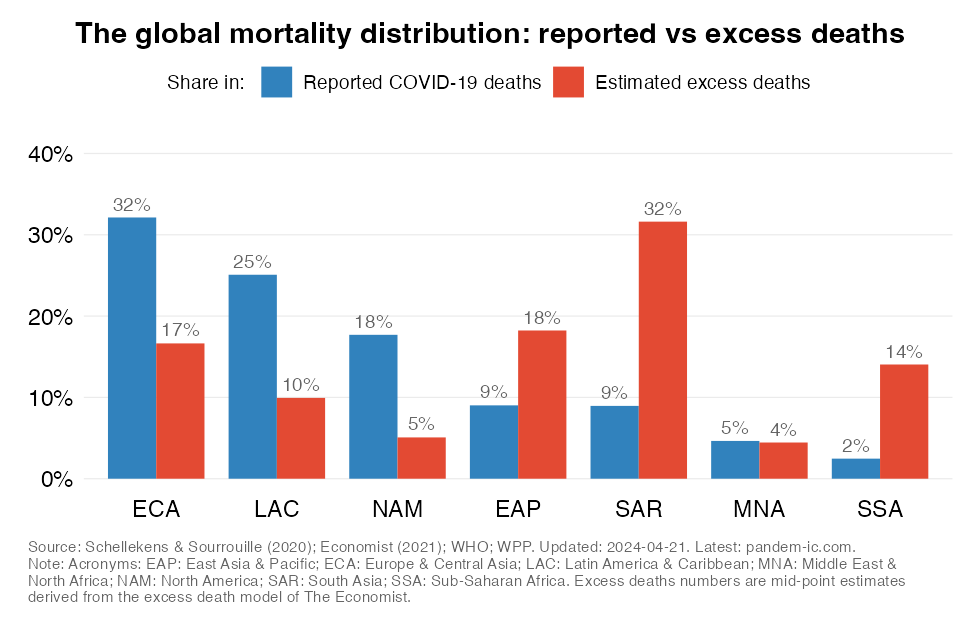
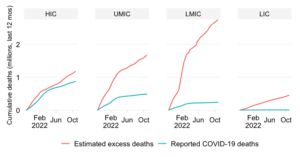
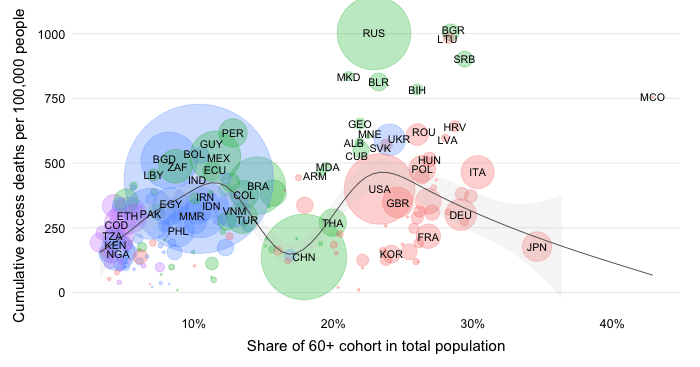
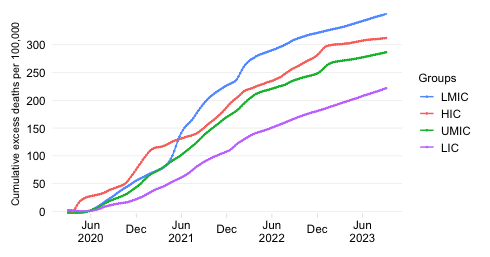
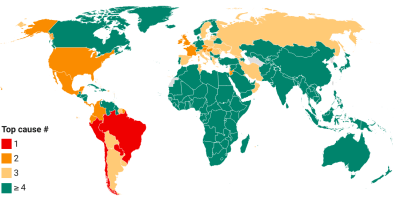
This chart contrasts two views about the global mortality distribution: one on the basis of officially reported data on COVID-19 mortality and another one that uses estimates of excess deaths.
The first bar shows the current share in reported COVID-19 deaths across World Bank regions. These are cumulative numbers since early 2020 based on official sources of data, which with exception of a few countries do not include adjustments for excess deaths.
The second bar shows the mortality distribution through the lens of excess death estimates. These concern estimates of all-cause mortality over and beyond what one would expect in “normal times”. They do capture more broadly the effect of the pandemic as the estimates are not purely limited to COVID-19 mortality. More details on the methodology can be found in the note below.