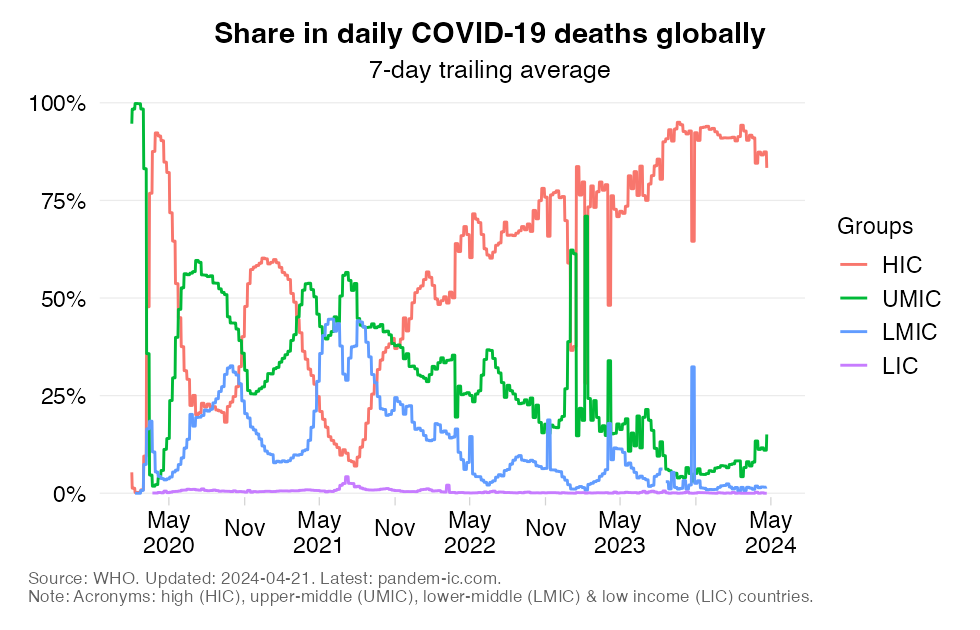
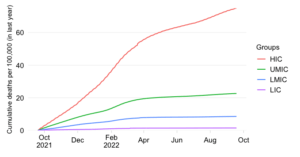
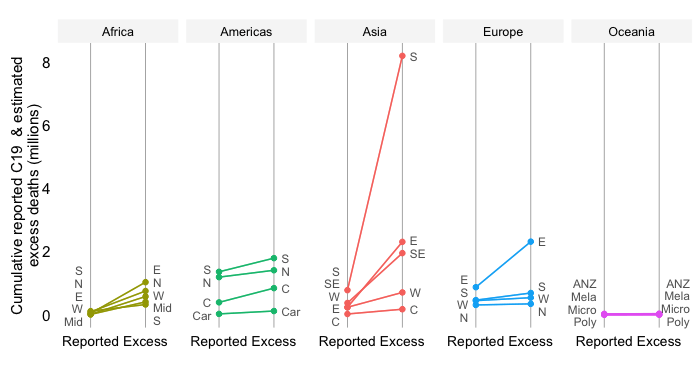
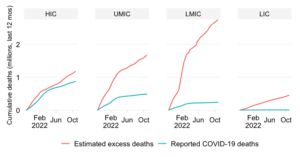
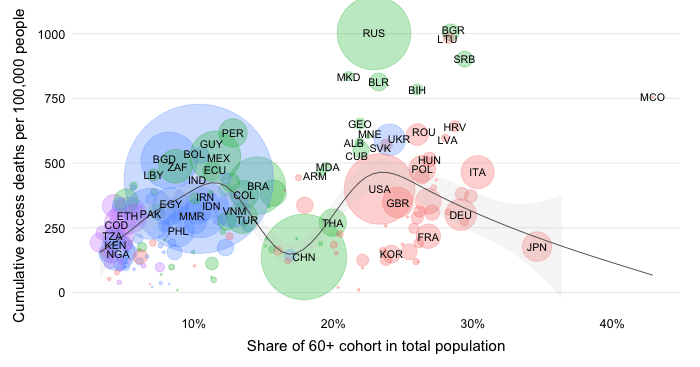
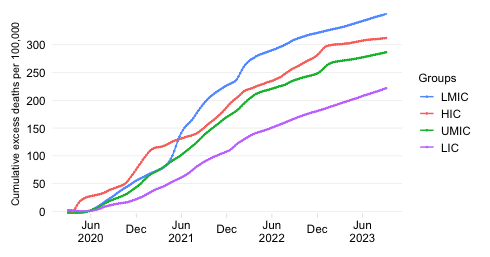
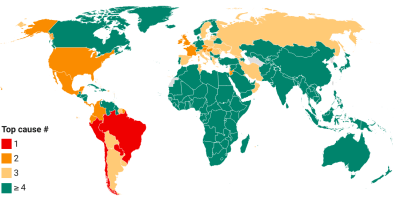
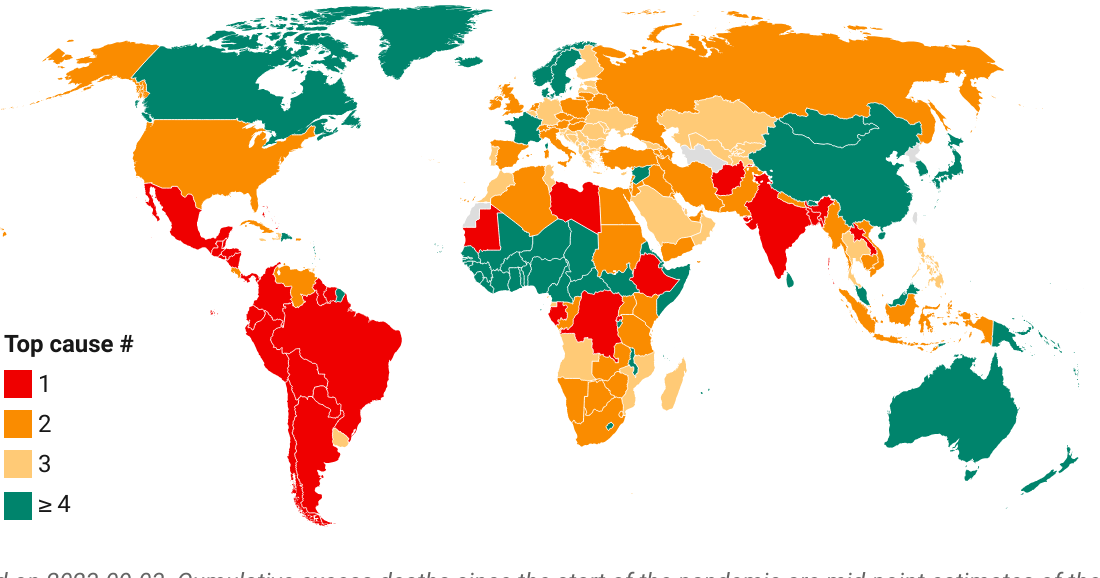
Share in daily confirmed COVID-19 deaths 7-day trailing average
EXPLAINER
This chart shows the evolution over time of the distribution of daily COVID-19 mortality across World Bank income groups. It calculates for each income group the share in daily COVID-19 mortality globally. To remove intra-week volatility in the reported data, the share is transformed into a 7-day trailing average by dividing the 7-day trailing averages of the numerator and denominator (7-day trailing average refers to the average value of the latest observation and the preceding 6 days).
The indicator reflects an absolute concept of mortality in that it expresses how the absolute death toll in a particular income group contributes to the global death tally. This differs fundamentally from the concept of the mortality rate, which expresses the absolute toll relative to population size and thus provides an indication of performance controlling for population size. The absolute numbers underpinning the mortality distribution shown here take the view that a life lost is a life lost, no matter where the person happened to live. It offers a valuable perspective on the absolute scale of the pandemic’s death toll.
It should be noted that the different income groups shown here are of very different population size dimensions. The global population as per the 2021 medium-variant projection of World Population Prospects is 7,866 million people,which is distributed as follows:
High-income countries (HICs): 1,212 million
Upper-middle-income countries (UMICs): 2,597 million
Lower-middle-income countries (LMICs): 3,374 million
Low-income countries (LICs): 683 million
In light of these differences in population size, we expect large differences in the distribution of absolute mortality even if mortality rates were constant across groups.