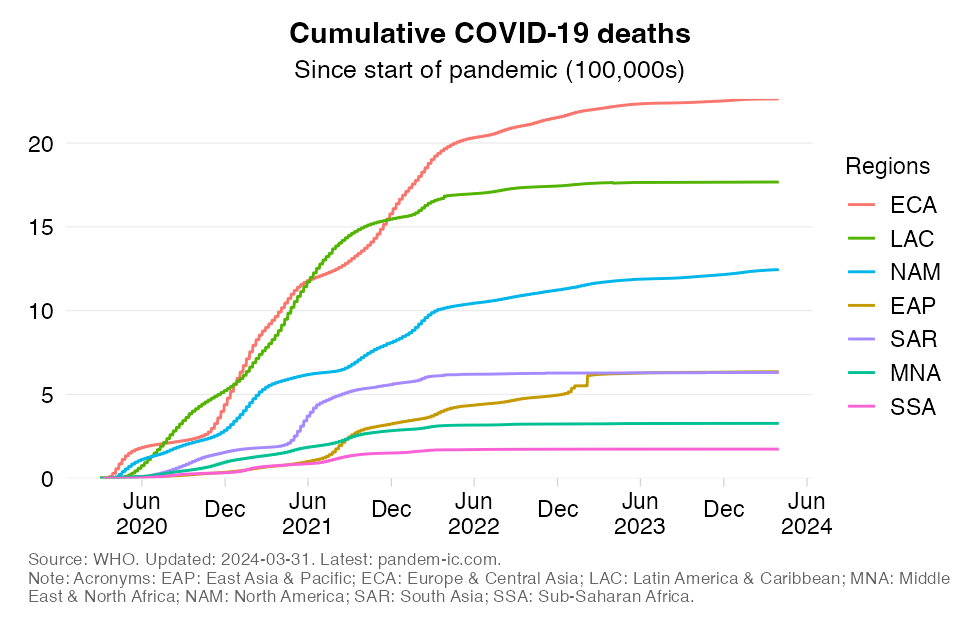
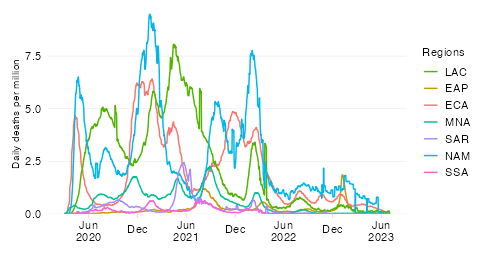
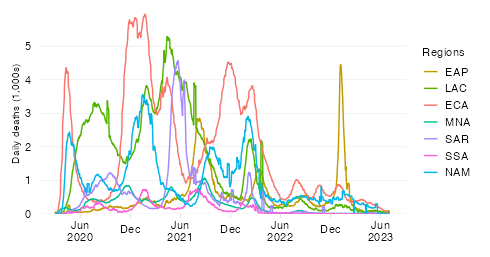
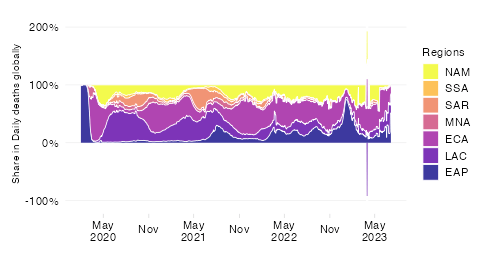
Cumulative confirmed COVID-19 deaths since start of the pandemic
EXPLAINER
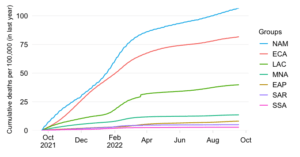
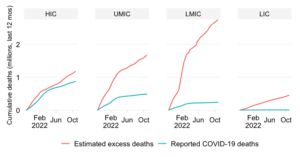
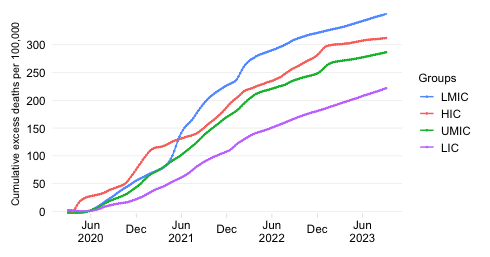
This chart shows the evolution over time of the cumulative COVID-19 mortality toll in absolute numbers across World Bank regions.
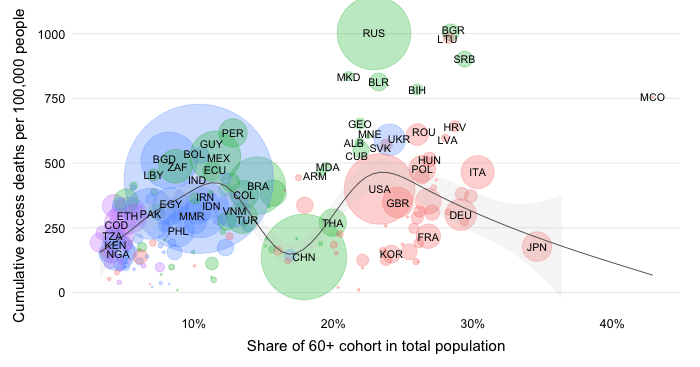
The absolute expression of the cumulative mortality toll is useful to highlight the the contribution of countries or groups of countries to the global total. Mortality rates, which express the absolute toll relative to population size, provide an indication of performance controlling for population size. The absolute numbers however take the view that a life lost is a life lost, no matter where the person happened to live. It offers a valuable perspective on the absolute scale of the pandemic’s death toll.
It should be noted that the different regional groups shown here are of very different population size dimensions. The global population as per the 2021 medium-variant projection of World Population Prospects is 7,866 million people, which is distributed as follows:
East Asia & Pacific (EAP): 2,392 million
Europe & Central Asia (ECA): 930 million
Latin America & Caribbean (LAC): 655 million
Middle East & North Africa (MNA): 472 million
North America (NAM): 374 million
South Asia (SAR): 1,877 million
Sub-Saharan Africa (SSA): 1,166 million
In light of these differences in population size, we expect large differences in absolute mortality numbers even if mortality rates were constant across groups.